

Table of Content
Scaling AI Data Extraction with BullMQ: A Developer’s Guide to Asynchronous Processing
By:
Soumya Ranjan Sahoo
12 Nov 2025
The most frequent problem facing many developers who have come up with AI-powered data extraction is the processing times which take between 30-60 seconds per request. This poses serious issues in production code as the synchronous processing of the main thread causes bad user experience and even delays.
Common Challenges:
The processes of AI data extraction that require 30-60 seconds.
Blocking of main application thread.
Risk of request timeouts
Unsatisfactory user experience with concurrent processing.
Requirement of re-try mechanisms and error management.
The solution? An Implementation of a Queue Processor. We will be using the BullMQ and Redis as the queue processor.
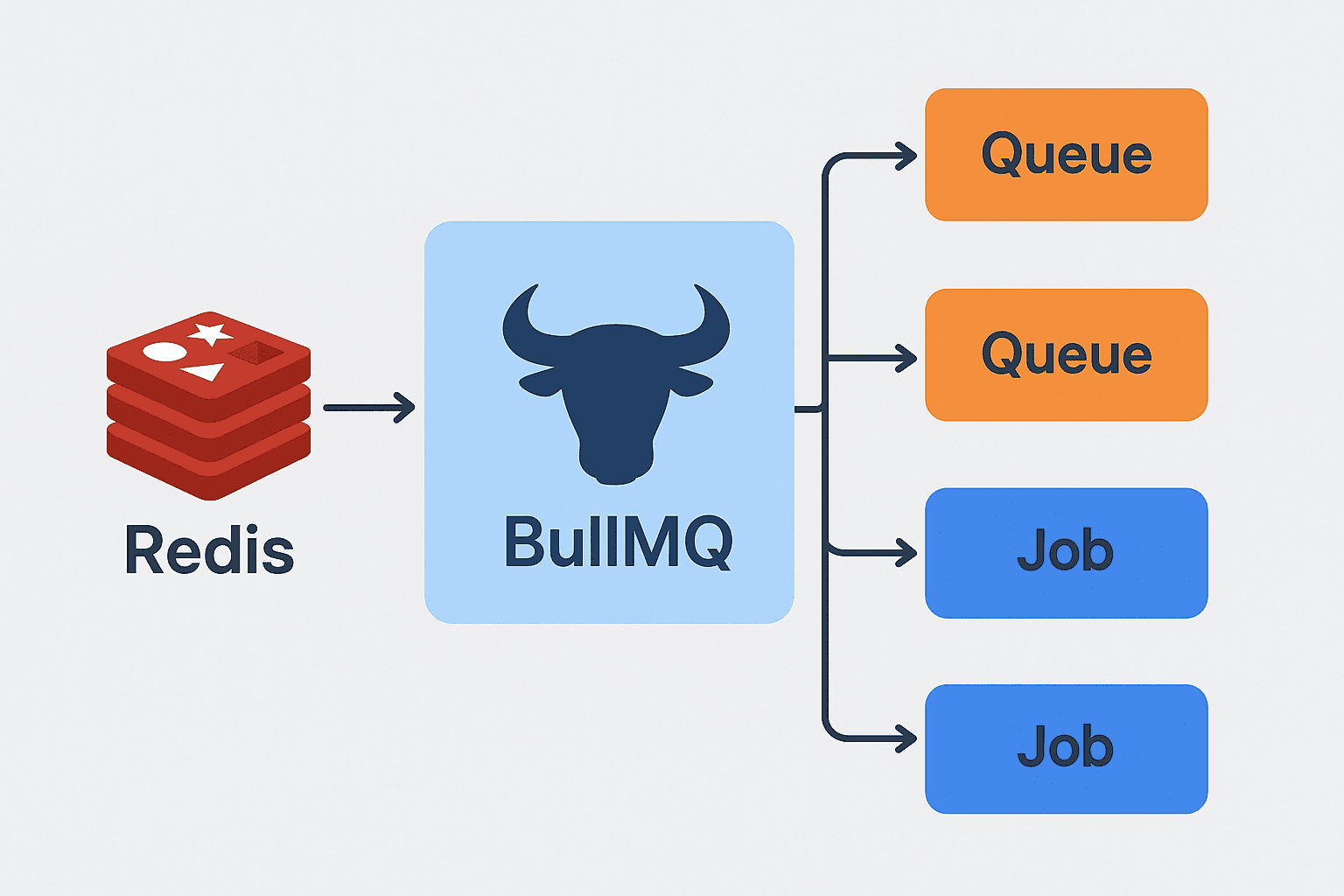
Why BullMQ? The Technical Decision
BullMQ is distinguished by a number of features that are important in the strong processing of asynchronous processing:
Persistence Redis based: Jobs are not lost on restart of a server.
In-software retry logic: Exponential backoff retry.
Parallel processing: Jobs can be processed by more than one worker at the same time.
Job prioritization: Firstly, critical tasks may be handled.
Progress monitoring: Job monitoring in real time.
Event-driven architecture: Ideal with node.js applications.
Prerequisites and Setup
Install Dependencies
npm install bullmq ioredis # or yarn add bullmq ioredis
Redis Setup
Run Redis on your system. The easiest approach is Docker:
docker run -d -p 6379:6379 redis:alpine
Or install locally:
macOS:
brew install redisWindows: Install Redis on Windows | Docs
Ubuntu:
sudo apt-get install redis-server
Environment Configuration
Add these to your .env file:
REDIS_HOST=localhost REDIS_PORT=6379 REDIS_PASSWORD=your_redis_password WORKER_CONCURRENCY=5
Implementation: Step-by-Step Guide
Let’s walk through transforming a synchronous Node.js process into asynchronous using BullMQ.
Create a Queue Manager
// utils/QueueManager.ts import { Queue } from 'bullmq'; import Redis from 'ioredis'; export class QueueManager { private queues = new Map(); private redis: Redis; constructor() { this.redis = new Redis({ host: process.env.REDIS_HOST || 'localhost', port: parseInt(process.env.REDIS_PORT || '6379') }); } createQueue(name: string, options = {}) { const queue = new Queue(name, { connection: this.redis, ...options }); this.queues.set(name, queue); return queue; } async addJob(queueName: string, jobName: string, data: any, options = {}) { const queue = this.queues.get(queueName); return await queue.add(jobName, data, options); } } export default new QueueManager();
Add Jobs to the Queue
// services/AIDataExtractionService.ts import queueManager from '../utils/QueueManager'; export class AIDataExtractionService { static async processDataExtraction(data: any) { queueManager.createQueue('ai-extraction'); return await queueManager.addJob('ai-extraction', 'extract-data', data, { priority: 1 }); } }
Worker to Process Jobs
// workers/AIDataExtractionWorker.ts import { Worker } from 'bullmq'; import Redis from 'ioredis'; const redis = new Redis('localhost'); const aiExtractionWorker = new Worker('ai-extraction', async (job) => { // Stepwise: prepare, call AI, process results await job.updateProgress(20); // ...work await job.updateProgress(100); });
Application Integration
In the main application, queue jobs instead of running them synchronously:
app.post('/api/extract-data', async (req, res) => { const result = await AIDataExtractionService.processDataExtraction(req.body.data); res.json({ jobId: result.id, status: 'queued' }); });
Monitor the job status:
app.get('/api/job-status/:jobId', async (req, res) => { const job = await queueManager.getJob('ai-extraction', req.params.jobId); res.json({ jobId: job.id, status: await job.getState(), progress: job.progress }); });
Performance Comparison
Watch what happens to the application with the use of async processing. (Before/After comparison or metrics may be inserted here where possible)
Monitoring and Management
Track the jobs through Bull Board. You are able to see waiting jobs, active jobs, completed jobs, and failed jobs, re-try failed jobs, pause the queue, and clean up completed jobs all on a clean dashboard.
Advanced Features and Best Practices
Parallel Job Processing
The application can be scaled by executing more than one worker instance processing jobs in the same queue. The various jobs can be done in parallel by each worker, which has a significant effect on increasing throughput and decreasing processing time of high workload.
// Start multiple workers for parallel processing const worker1 = new Worker('ai-extraction', async (job) => { console.log(`Worker 1 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); const worker2 = new Worker('ai-extraction', async (job) => { console.log(`Worker 2 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); // Each worker can process 5 jobs concurrently = 10 total parallel jobs
Retry Logic and Backoff
BullMQ will automatically re-run jobs that fail with an exponential backoff to ensure that the server is not overwhelmed by temporary failures. You are able to set up the number of attempts and backoff plans to make sure that job processing is resilient.
// Configure retry logic with exponential backoff await queue.add('extract-data', jobData, { attempts: 5, backoff: { type: 'exponential', delay: 2000 // Start with 2s, then 4s, 8s, 16s, 32s } }); // Or use custom backoff strategy await queue.add('extract-data', jobData, { attempts: 3, backoff: { type: 'fixed', delay: 5000 // Fixed 5-second delay between retries } });
Troubleshooting Common Pitfalls
Memory Issues
Configure Redis cleanup:
defaultJobOptions: { removeOnComplete: 10, // Keep only recent jobs removeOnFail: 50 }
Worker Crashes
Add error handling and alerting in worker:
worker.on('error', err => { // Log and alert });
Job Timeouts
Tune settings for long jobs:
settings: { stalledInterval: 30 * 1000, maxStalledCount: 1 }
Reference Links
Conclusion
BullMQ with Redis transforms slow, synchronous AI data extraction into fast, scalable, and reliable asynchronous workflows in Node.js. By leveraging parallel processing, retry logic, and real-time monitoring, developers can boost performance, prevent timeouts, and deliver a smoother user experience. Implementing this queue-based approach ensures your AI applications remain efficient, resilient, and production-ready.
Frequently Asked Questions (FAQs)
1. How does BullMQ compare to RabbitMQ or Kafka?
A. BullMQ is ideal in the processing of jobs in Node.js but with easy installation. RabbitMQ is appropriate to the enterprise microservices messaging and intricate routing. Kafka is a high throughput data streaming tool.
Choose based on your use case:
Background jobs: BullMQ
Message brokering: RabbitMQ
Real-time data pipelines: Kafka
2. Do I need Redis installed for BullMQ to work?
A. Yes. In BullMQ, the job persistence and queue management use Redis (version 6.2.0+) as a job persistence and queue management backend. Redis could be run locally or with Docker or managed services such as AWS ElastiCache or Redis Cloud.
3. How can I monitor and manage BullMQ jobs in production?
A. Visual monitoring, with real-time job status, retries and metrics Use Bull Board. Prometheus/Grafana can also be integrated to get production-grade dashboards. Bull Board is easily compatible with Express, Fastify, or NestJS.
4. What happens to jobs if my server crashes?
A. Jobs are persisted in Redis and survive crashes or restarts.
When your application recovers, BullMQ automatically processes incomplete jobs with built-in retry logic and exponential backoff for reliability.
The most frequent problem facing many developers who have come up with AI-powered data extraction is the processing times which take between 30-60 seconds per request. This poses serious issues in production code as the synchronous processing of the main thread causes bad user experience and even delays.
Common Challenges:
The processes of AI data extraction that require 30-60 seconds.
Blocking of main application thread.
Risk of request timeouts
Unsatisfactory user experience with concurrent processing.
Requirement of re-try mechanisms and error management.
The solution? An Implementation of a Queue Processor. We will be using the BullMQ and Redis as the queue processor.
Why BullMQ? The Technical Decision
BullMQ is distinguished by a number of features that are important in the strong processing of asynchronous processing:
Persistence Redis based: Jobs are not lost on restart of a server.
In-software retry logic: Exponential backoff retry.
Parallel processing: Jobs can be processed by more than one worker at the same time.
Job prioritization: Firstly, critical tasks may be handled.
Progress monitoring: Job monitoring in real time.
Event-driven architecture: Ideal with node.js applications.
Prerequisites and Setup
Install Dependencies
npm install bullmq ioredis # or yarn add bullmq ioredis
Redis Setup
Run Redis on your system. The easiest approach is Docker:
docker run -d -p 6379:6379 redis:alpine
Or install locally:
macOS:
brew install redisWindows: Install Redis on Windows | Docs
Ubuntu:
sudo apt-get install redis-server
Environment Configuration
Add these to your .env file:
REDIS_HOST=localhost REDIS_PORT=6379 REDIS_PASSWORD=your_redis_password WORKER_CONCURRENCY=5
Implementation: Step-by-Step Guide
Let’s walk through transforming a synchronous Node.js process into asynchronous using BullMQ.
Create a Queue Manager
// utils/QueueManager.ts import { Queue } from 'bullmq'; import Redis from 'ioredis'; export class QueueManager { private queues = new Map(); private redis: Redis; constructor() { this.redis = new Redis({ host: process.env.REDIS_HOST || 'localhost', port: parseInt(process.env.REDIS_PORT || '6379') }); } createQueue(name: string, options = {}) { const queue = new Queue(name, { connection: this.redis, ...options }); this.queues.set(name, queue); return queue; } async addJob(queueName: string, jobName: string, data: any, options = {}) { const queue = this.queues.get(queueName); return await queue.add(jobName, data, options); } } export default new QueueManager();
Add Jobs to the Queue
// services/AIDataExtractionService.ts import queueManager from '../utils/QueueManager'; export class AIDataExtractionService { static async processDataExtraction(data: any) { queueManager.createQueue('ai-extraction'); return await queueManager.addJob('ai-extraction', 'extract-data', data, { priority: 1 }); } }
Worker to Process Jobs
// workers/AIDataExtractionWorker.ts import { Worker } from 'bullmq'; import Redis from 'ioredis'; const redis = new Redis('localhost'); const aiExtractionWorker = new Worker('ai-extraction', async (job) => { // Stepwise: prepare, call AI, process results await job.updateProgress(20); // ...work await job.updateProgress(100); });
Application Integration
In the main application, queue jobs instead of running them synchronously:
app.post('/api/extract-data', async (req, res) => { const result = await AIDataExtractionService.processDataExtraction(req.body.data); res.json({ jobId: result.id, status: 'queued' }); });
Monitor the job status:
app.get('/api/job-status/:jobId', async (req, res) => { const job = await queueManager.getJob('ai-extraction', req.params.jobId); res.json({ jobId: job.id, status: await job.getState(), progress: job.progress }); });
Performance Comparison
Watch what happens to the application with the use of async processing. (Before/After comparison or metrics may be inserted here where possible)
Monitoring and Management
Track the jobs through Bull Board. You are able to see waiting jobs, active jobs, completed jobs, and failed jobs, re-try failed jobs, pause the queue, and clean up completed jobs all on a clean dashboard.
Advanced Features and Best Practices
Parallel Job Processing
The application can be scaled by executing more than one worker instance processing jobs in the same queue. The various jobs can be done in parallel by each worker, which has a significant effect on increasing throughput and decreasing processing time of high workload.
// Start multiple workers for parallel processing const worker1 = new Worker('ai-extraction', async (job) => { console.log(`Worker 1 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); const worker2 = new Worker('ai-extraction', async (job) => { console.log(`Worker 2 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); // Each worker can process 5 jobs concurrently = 10 total parallel jobs
Retry Logic and Backoff
BullMQ will automatically re-run jobs that fail with an exponential backoff to ensure that the server is not overwhelmed by temporary failures. You are able to set up the number of attempts and backoff plans to make sure that job processing is resilient.
// Configure retry logic with exponential backoff await queue.add('extract-data', jobData, { attempts: 5, backoff: { type: 'exponential', delay: 2000 // Start with 2s, then 4s, 8s, 16s, 32s } }); // Or use custom backoff strategy await queue.add('extract-data', jobData, { attempts: 3, backoff: { type: 'fixed', delay: 5000 // Fixed 5-second delay between retries } });
Troubleshooting Common Pitfalls
Memory Issues
Configure Redis cleanup:
defaultJobOptions: { removeOnComplete: 10, // Keep only recent jobs removeOnFail: 50 }
Worker Crashes
Add error handling and alerting in worker:
worker.on('error', err => { // Log and alert });
Job Timeouts
Tune settings for long jobs:
settings: { stalledInterval: 30 * 1000, maxStalledCount: 1 }
Reference Links
Conclusion
BullMQ with Redis transforms slow, synchronous AI data extraction into fast, scalable, and reliable asynchronous workflows in Node.js. By leveraging parallel processing, retry logic, and real-time monitoring, developers can boost performance, prevent timeouts, and deliver a smoother user experience. Implementing this queue-based approach ensures your AI applications remain efficient, resilient, and production-ready.
Frequently Asked Questions (FAQs)
1. How does BullMQ compare to RabbitMQ or Kafka?
A. BullMQ is ideal in the processing of jobs in Node.js but with easy installation. RabbitMQ is appropriate to the enterprise microservices messaging and intricate routing. Kafka is a high throughput data streaming tool.
Choose based on your use case:
Background jobs: BullMQ
Message brokering: RabbitMQ
Real-time data pipelines: Kafka
2. Do I need Redis installed for BullMQ to work?
A. Yes. In BullMQ, the job persistence and queue management use Redis (version 6.2.0+) as a job persistence and queue management backend. Redis could be run locally or with Docker or managed services such as AWS ElastiCache or Redis Cloud.
3. How can I monitor and manage BullMQ jobs in production?
A. Visual monitoring, with real-time job status, retries and metrics Use Bull Board. Prometheus/Grafana can also be integrated to get production-grade dashboards. Bull Board is easily compatible with Express, Fastify, or NestJS.
4. What happens to jobs if my server crashes?
A. Jobs are persisted in Redis and survive crashes or restarts.
When your application recovers, BullMQ automatically processes incomplete jobs with built-in retry logic and exponential backoff for reliability.
The most frequent problem facing many developers who have come up with AI-powered data extraction is the processing times which take between 30-60 seconds per request. This poses serious issues in production code as the synchronous processing of the main thread causes bad user experience and even delays.
Common Challenges:
The processes of AI data extraction that require 30-60 seconds.
Blocking of main application thread.
Risk of request timeouts
Unsatisfactory user experience with concurrent processing.
Requirement of re-try mechanisms and error management.
The solution? An Implementation of a Queue Processor. We will be using the BullMQ and Redis as the queue processor.
Why BullMQ? The Technical Decision
BullMQ is distinguished by a number of features that are important in the strong processing of asynchronous processing:
Persistence Redis based: Jobs are not lost on restart of a server.
In-software retry logic: Exponential backoff retry.
Parallel processing: Jobs can be processed by more than one worker at the same time.
Job prioritization: Firstly, critical tasks may be handled.
Progress monitoring: Job monitoring in real time.
Event-driven architecture: Ideal with node.js applications.
Prerequisites and Setup
Install Dependencies
npm install bullmq ioredis # or yarn add bullmq ioredis
Redis Setup
Run Redis on your system. The easiest approach is Docker:
docker run -d -p 6379:6379 redis:alpine
Or install locally:
macOS:
brew install redisWindows: Install Redis on Windows | Docs
Ubuntu:
sudo apt-get install redis-server
Environment Configuration
Add these to your .env file:
REDIS_HOST=localhost REDIS_PORT=6379 REDIS_PASSWORD=your_redis_password WORKER_CONCURRENCY=5
Implementation: Step-by-Step Guide
Let’s walk through transforming a synchronous Node.js process into asynchronous using BullMQ.
Create a Queue Manager
// utils/QueueManager.ts import { Queue } from 'bullmq'; import Redis from 'ioredis'; export class QueueManager { private queues = new Map(); private redis: Redis; constructor() { this.redis = new Redis({ host: process.env.REDIS_HOST || 'localhost', port: parseInt(process.env.REDIS_PORT || '6379') }); } createQueue(name: string, options = {}) { const queue = new Queue(name, { connection: this.redis, ...options }); this.queues.set(name, queue); return queue; } async addJob(queueName: string, jobName: string, data: any, options = {}) { const queue = this.queues.get(queueName); return await queue.add(jobName, data, options); } } export default new QueueManager();
Add Jobs to the Queue
// services/AIDataExtractionService.ts import queueManager from '../utils/QueueManager'; export class AIDataExtractionService { static async processDataExtraction(data: any) { queueManager.createQueue('ai-extraction'); return await queueManager.addJob('ai-extraction', 'extract-data', data, { priority: 1 }); } }
Worker to Process Jobs
// workers/AIDataExtractionWorker.ts import { Worker } from 'bullmq'; import Redis from 'ioredis'; const redis = new Redis('localhost'); const aiExtractionWorker = new Worker('ai-extraction', async (job) => { // Stepwise: prepare, call AI, process results await job.updateProgress(20); // ...work await job.updateProgress(100); });
Application Integration
In the main application, queue jobs instead of running them synchronously:
app.post('/api/extract-data', async (req, res) => { const result = await AIDataExtractionService.processDataExtraction(req.body.data); res.json({ jobId: result.id, status: 'queued' }); });
Monitor the job status:
app.get('/api/job-status/:jobId', async (req, res) => { const job = await queueManager.getJob('ai-extraction', req.params.jobId); res.json({ jobId: job.id, status: await job.getState(), progress: job.progress }); });
Performance Comparison
Watch what happens to the application with the use of async processing. (Before/After comparison or metrics may be inserted here where possible)
Monitoring and Management
Track the jobs through Bull Board. You are able to see waiting jobs, active jobs, completed jobs, and failed jobs, re-try failed jobs, pause the queue, and clean up completed jobs all on a clean dashboard.
Advanced Features and Best Practices
Parallel Job Processing
The application can be scaled by executing more than one worker instance processing jobs in the same queue. The various jobs can be done in parallel by each worker, which has a significant effect on increasing throughput and decreasing processing time of high workload.
// Start multiple workers for parallel processing const worker1 = new Worker('ai-extraction', async (job) => { console.log(`Worker 1 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); const worker2 = new Worker('ai-extraction', async (job) => { console.log(`Worker 2 processing job ${job.id}`); return await processAIExtraction(job.data); }, { connection: redis, concurrency: 5 }); // Each worker can process 5 jobs concurrently = 10 total parallel jobs
Retry Logic and Backoff
BullMQ will automatically re-run jobs that fail with an exponential backoff to ensure that the server is not overwhelmed by temporary failures. You are able to set up the number of attempts and backoff plans to make sure that job processing is resilient.
// Configure retry logic with exponential backoff await queue.add('extract-data', jobData, { attempts: 5, backoff: { type: 'exponential', delay: 2000 // Start with 2s, then 4s, 8s, 16s, 32s } }); // Or use custom backoff strategy await queue.add('extract-data', jobData, { attempts: 3, backoff: { type: 'fixed', delay: 5000 // Fixed 5-second delay between retries } });
Troubleshooting Common Pitfalls
Memory Issues
Configure Redis cleanup:
defaultJobOptions: { removeOnComplete: 10, // Keep only recent jobs removeOnFail: 50 }
Worker Crashes
Add error handling and alerting in worker:
worker.on('error', err => { // Log and alert });
Job Timeouts
Tune settings for long jobs:
settings: { stalledInterval: 30 * 1000, maxStalledCount: 1 }
Reference Links
Conclusion
BullMQ with Redis transforms slow, synchronous AI data extraction into fast, scalable, and reliable asynchronous workflows in Node.js. By leveraging parallel processing, retry logic, and real-time monitoring, developers can boost performance, prevent timeouts, and deliver a smoother user experience. Implementing this queue-based approach ensures your AI applications remain efficient, resilient, and production-ready.
Frequently Asked Questions (FAQs)
1. How does BullMQ compare to RabbitMQ or Kafka?
A. BullMQ is ideal in the processing of jobs in Node.js but with easy installation. RabbitMQ is appropriate to the enterprise microservices messaging and intricate routing. Kafka is a high throughput data streaming tool.
Choose based on your use case:
Background jobs: BullMQ
Message brokering: RabbitMQ
Real-time data pipelines: Kafka
2. Do I need Redis installed for BullMQ to work?
A. Yes. In BullMQ, the job persistence and queue management use Redis (version 6.2.0+) as a job persistence and queue management backend. Redis could be run locally or with Docker or managed services such as AWS ElastiCache or Redis Cloud.
3. How can I monitor and manage BullMQ jobs in production?
A. Visual monitoring, with real-time job status, retries and metrics Use Bull Board. Prometheus/Grafana can also be integrated to get production-grade dashboards. Bull Board is easily compatible with Express, Fastify, or NestJS.
4. What happens to jobs if my server crashes?
A. Jobs are persisted in Redis and survive crashes or restarts.
When your application recovers, BullMQ automatically processes incomplete jobs with built-in retry logic and exponential backoff for reliability.
Explore our services










Explore other blogs
Explore other blogs












let's get in touch
Have a Project idea?
Connect with us for a free consultation !
Confidentiality with NDA
Understanding the core business.
Brainstorm with our leaders
Daily & Weekly Updates
Super competitive pricing
let's get in touch
Have a Project idea?
Connect with us for a free consultation !
Confidentiality with NDA
Understanding the core business.
Brainstorm with our leaders
Daily & Weekly Updates
Super competitive pricing
DEFINITELY POSSIBLE
Our Services
Technologies
Subscribe to our newsletter:
Find us on:



Crafted & maintained with ❤️ by our Smartees | Copyright © 2025 - Smartters Softwares PVT. LTD.
Our Services
Technologies
Subscribe to our newsletter:
Find us on:
Created with ❤️ by our Smartees
Copyright © 2025 - Smartters Softwares PVT. LTD.